Vector Search
Generative AI menjadi salah bidang yang paling diminati belakangan ini karena membuka kemungkinan-kemungkinan baru apa yang mesin bisa lakukan. Contoh sederhananya adalah meminta bantuan mesin untuk menulis code dan menulis blog. Hal ini dimungkinkan karena mesin sudah menguasai bahasa vektor.
Apa itu vektor? Sederhananya, kumpulan angka. Ini adalah contoh vektor data pribadi seorang karyawan yang memuat data pribadi seperti tinggi badan, berat badan, minus mata kiri dan kanan, tingkat popularitas, IQ: [174.2, 77.4, -2.5, -2.0, 5.0, 99.9].
Jika suatu hari seseorang resign dari pekerjaannya, dan perusahaan ingin mencari pengganti yang serupa, maka perusahaan dapat mengambil vektor data pribadi karyawan lama tersebut, lalu memilah kandidat baru yang memiliki vektor paling mirip (perbedaan angka-angkanya paling kecil).
Ada beberapa metrik jarak yang bisa dipakai untuk menyetakan seberapa (tidak) mirip 2 vektor. Jika semua selisih nilai kedua vektor pada elemen yang sama dijumlahkan, itu menggunakan jarak Manhattan (L1). Jika jarak diukur sebagaimana kita secara intuitif mengukur jarak antara 2 titik (ingat-ingat rumus Pythagoras), digunakanlah jarak Euclidean (L2). Kalau jarak ditentukan dari besar sudut yang dibentuk oleh kedua vektor tersebut, maka digunakan jarak cosine, atau jika panjang vektor juga menjadi pertimbangan, jarak perkalian titik (dot product).
Tentu ada kekurangan jika kita menggunakan data yang mentah sebagai vektor untuk diproses. Pertama, perusahaan mungkin tidak peduli dengan minus mata kanan. Kedua, tinggi badan dan berat badan meskipun jika digunakan sebagai fitur terpisah tidak berguna, jika digunakan bersamaan mungkin bisa menjadi prediktor tingkat stres yang bisa ditolerir seseorang (mungkin bagus juga jika ditambahkan tingkat screen time dan konsumsi gula).
Bagaimana kita bisa mendesain vektor yang tepat untuk dibandingkan?
(Auto) Encoder
Semua jenis data dapat diubah menjadi vektor. Contohnya adalah data gambar. Di bawah ini adalah gambar merak dengan lebar 1600 pixel dan tinggi 1067 pixel. Karena gambar ini berwarna, maka ada 3 channel: R, G, B, untuk masing-masing pixel. Maka secara naif kita bisa buat vektor dengan panjang 3x1067x1600 = 5,121,600.

Berikut 2 gambar lain sebagai pembanding:


Pertama, jelas harus me-resize gambar agar ukurannya sama. Mesin tidak terlalu pintar untuk dapat membandingkan dua objek berukuran berbeda.
Cara naif membandingkan antar gambar adalah dengan mengubah ketiganya menjadi vektor berukuran 5,121,600 dan dilihat perbedaannya. Dengan cara seperti ini, gambar binatang 0 dan binatang 1 akan diangggap mirip karena sama-sama hijau.
Manusia tahu gambar binatang 2 lebih mirip binatang 0 karena sama-sama punya bulu, juga karena bentuk kepala dan badannya yang lebih mirip.
Bagaimana membangun vektor yang dapat mengekstrak informasi yang kita anggap lebih relevan tersebut?
Perkenalkan, autoencoder, anggota keluarga neural network yang mungkin paling cocok untuk pekerjaan ini. Autoencoder memiliki 2 bagian: encoding network, atau encoder, yang menghubungkan input layer dengan latent space, dan decoding network, atau decoder, yang menghubungkan latent space dengan output layer. Latent space sendiri adalah satu layer di tengah-tengah autoencoder yang memiliki jumlah node/dimensi yang sedikit sehingga berfungsi sebagai bottleneck.
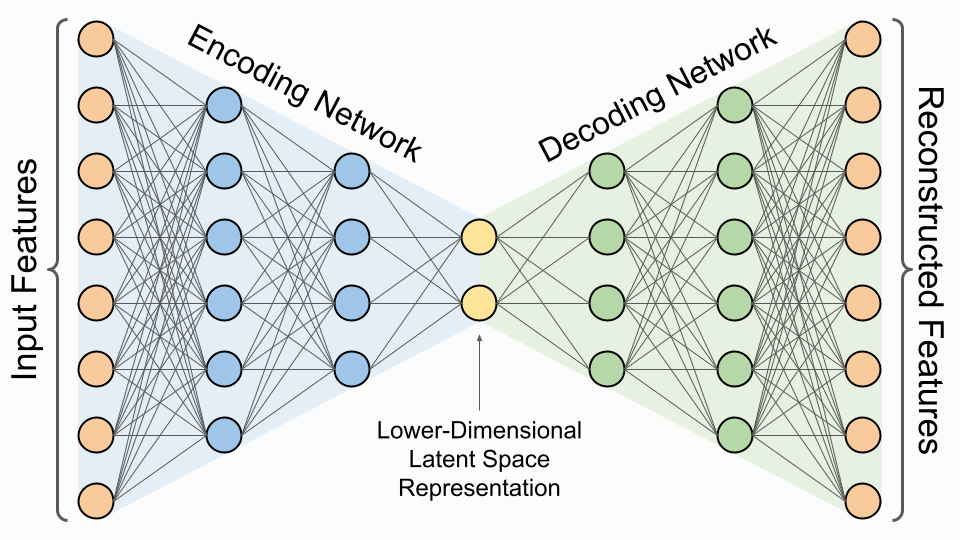
Pada saat training, autoencoder diberikan dataset dengan output yang sama dengan input, sehingga parameter-parameter weight dan bias di dalam network dilatih untuk dapat mengkonstruksi ulang gambar. Tugas ini menjadi tidak trivial karena informasi harus melewati bottleneck latent space berdimensi rendah.
Katakanlah saya ingin merepresentasikan semua gambar hanya dengan 10 angka, saya bisa buat autoencoder dengan latent space berdimensi 10. Katakanlah gambar binatang 0 punya nilai di latent space sebagai berikut: [0.3, 1.8, -2.2, 3.1, 1.7, 5.2, -5.7, 1.2, 3.2, -1.5]. Agar vektor ini bisa dikatakan representatif, maka saya harus dapat merekonstruksi ulang gambar awal (yang memiliki 5,121,600 angka) dengan 10 angka di vektor tersebut.
Jika proses training berjalan baik dan diperoleh model yang akurat (artinya hampir semua gambar pada dataset dapat direkonstruksi dengan cukup baik), artinya model encoder berhasil menangkap fitur-fitur yang penting dan merangkumnya di latent space. Selanjutnya kita bisa potong autoencoder dan mengambil bagian encoder-nya saja, untuk membangun vektor yang representatif dari suatu gambar. Vektor-vektor inilah yang nantinya digunakan untuk melakukan vector search.
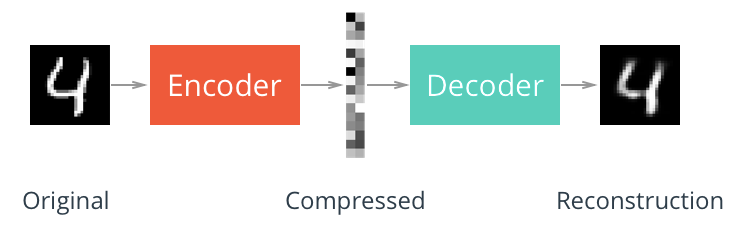
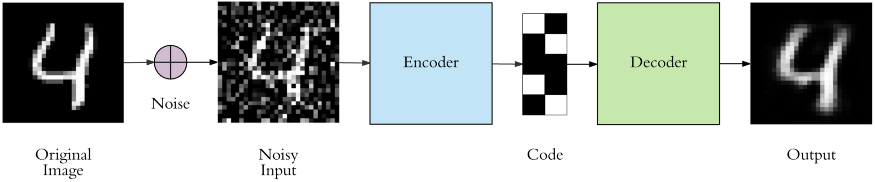
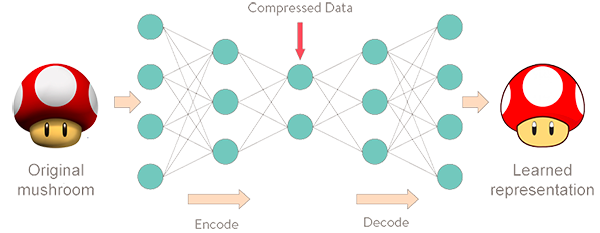
Encoder dapat juga dilihat sebagai metode kompresi data, yaitu mengecilkan file yang berukuran besar agar menghemat penyimpanan atau transfer data, dan untuk membangun ulang file aslinya digunakanlah decoder yang kompatibel, seperti solusi yang diberikan oleh WinRAR atau Kecilin.id.
Setelah bisa mendesain vektor yang menyimpan data yang relevan, saatnya kita melakukan vector search dengan lebih efisien.
Navigable Small World
Bayangkan kamu ingin berkunjung ke rumah temanmu yang di luar kota, dan dia berkata, “ini alamatku. Cari saja terminal bus yang paling dekat dari sini dan kamu akan aku jemput di sana.” Karena kamu tidak begitu familiar dengan kota temanmu, kamu berencana melihat daftar terminal yang ada di kota itu, dan dengan aplikasi Maps melihat jarak masing-masing terminal ke rumah temanmu itu.
Setelah mencari tahu, ternyata ada lebih dari seratus terminal di dalam daftar. Tentu mengecek jarak masing-masing terminal dari rumah temanmu akan memakan waktu lama. Saat itulah kamu terpikir sebuah cara untuk menuju (salah satu) terminal terdekat tanpa mengecek jarak semua terminal.
Pertama, kamu mulai berangkat dari terminal terdekat dari rumahmu. Di terminal, kamu memeriksa daftar terminal tujuan yang dilayani oleh bus yang mengantar penumpang dari terminal itu. Daftar itu berisi kira-kira 5 terminal, dan kamu tinggal memilih terminal tujuan yang paling dekat dengan rumah temanmu dan pergi ke sana.
Sesampainya di sana, kamu bisa lakukan hal yang sama lagi, berulang-ulang. Kamu baru berhenti ketika di terminal yang kamu capai, tidak ada lagi terminal tujuan yang jaraknya lebih dekat ke rumah temanmu daripada terminal kamu berada. Kamu bisa segera menelepon temanmu untuk dijemput di terminal itu.
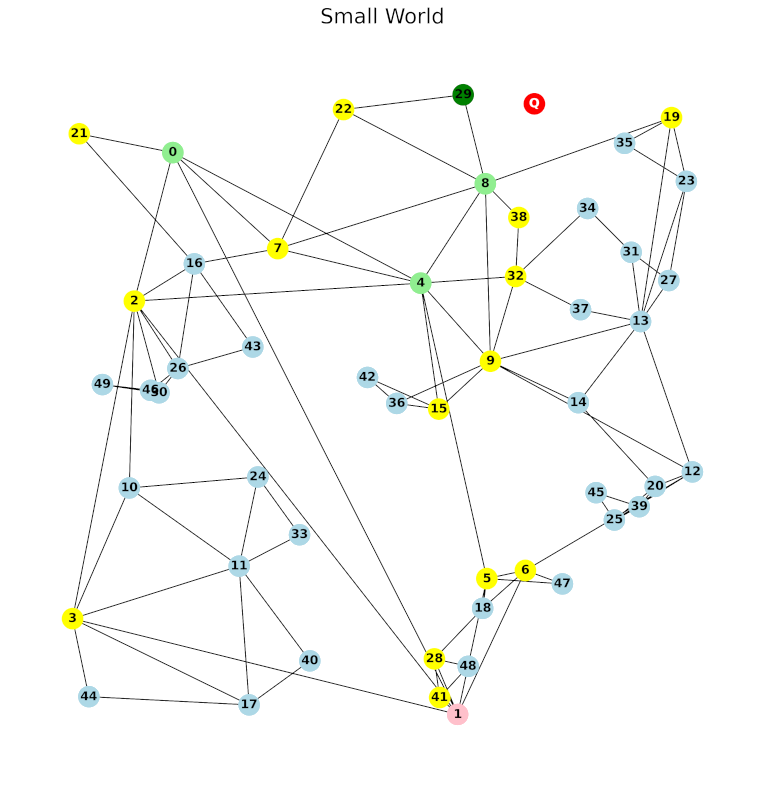
Dalam konteks vector search, setiap terminal adalah data/vektor di dalam database. Setiap data terhubung dengan beberapa data lain yang dekat dengannya.
Setiap ada data baru yang ditambahkan ke database, akan dicarikan sejumlah data di database yang paling dekar dengan data baru, dan dibuatkan rute dari data baru ke (dan dari, karena dua arah) masing-masing data terdekat tersebut. Begitulah graph NSW (navigable small world) dibangun.
HNSW (Hierarchical-NSW)
Sekarang bayangkan kalau kamu harus pergi ke rumah temanmu yang ada di Cimahi sedangkan kamu sedang ada di Medan. Meskipun memungkinkan, naik bus dari Medan ke Cimahi tidaklah efisien. Cara lebih baik adalah naik pesawat dari Medan ke Cengkareng, dilanjut naik kereta dari Cengkareng ke Jakarta, Jakarta ke Bandung, lalu Bandung ke Cimahi, dan terakhir baru naik bus di Cimahi untuk menuju terminal terdekat.
Karena jaringan transportasi di Indonesia terintegrasi dengan baik, setiap bandara memiliki stasiun, dan setiap stasiun memiliki terminal untuk memudahkan transportasi masyarakat (semoga masih ada jatah komisaris).
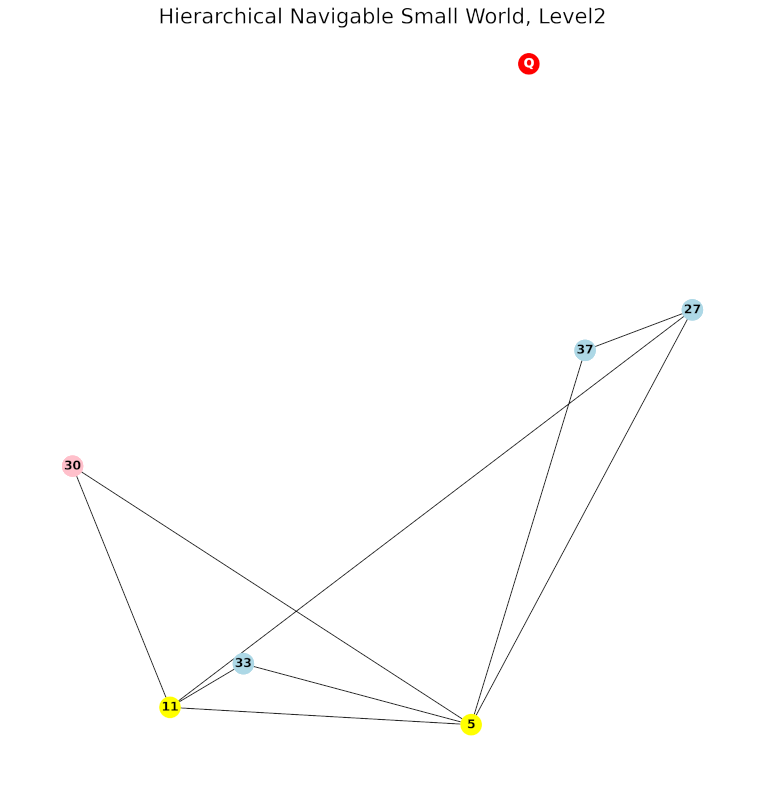
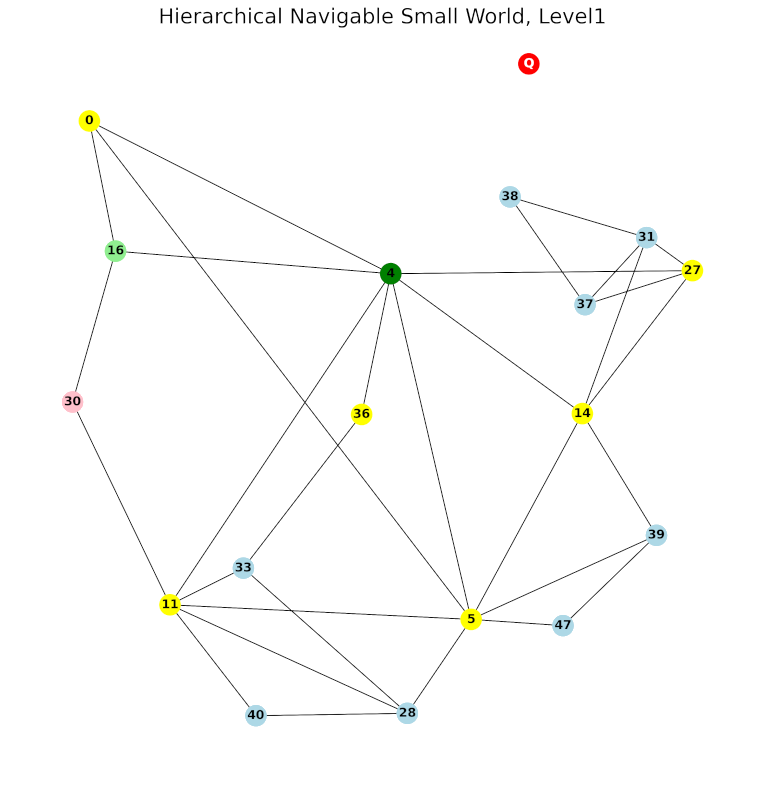

Dalam membangun HNSW, yang perlu diperhatikan adalah jumlah node pada tiap layer. Sebagaimana jumlah stasiun lebih sedikit daripada jumlah terminal, dan jumlah bandara lebih sedikit daripada jumlah stasiun, jumlah node di suatu layer harus lebih sedikit daripada layer-layer di bawahnya. (maaf aku menggunakan level dan layer secara bergantian)
Secara teknis, jika ada data untuk ditambahkan sebagai node baru, pertama-tama akan ditentukan pada level tertinggi berapa dia ada. Selanjutnya node akan ditambahkan pada level tersebut dan semua level di bawahnya. Pada semua level yang ditambahkan node baru, dilakukan proses pencarian beberapa node terdekat untuk dihubungkan seperti pada NSW.
Implementasi Menggunakan Numpy
Berikut notebook yang saya gunakan saat membangun HNSW langkah-demi-langkah. Saya juga membuat backend service untuk membantu visualisasi metode vector search dengan HNSW dan juga frontend untuk memudahkan mengaksesnya, di dalam repo fathiyul/hnsw-viz.
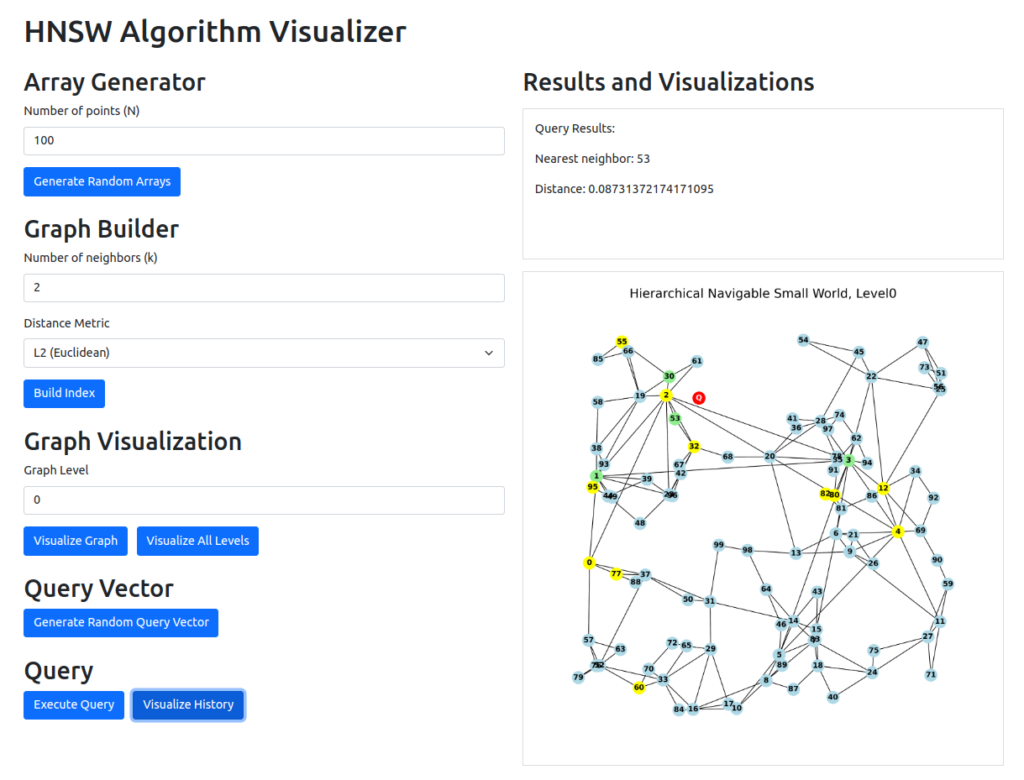
Tidak ada penjelasan lebih lanjut, baca saja code-nya dan kabari jika menemukan kesalahan 😀
Saya mengerjakan ini karena banyak layanan vector database saat ini, dan kebanyakan tutorial untuk melakukan search nya adalah tutorial menggunakan API dari masing-masing layanan yang berbeda.
Meskipun menggunakan API sangat membantu, ada perbedaan antara AI engineer dan API engineer, perbedaan satu token/karakter yang membuat vektor representasinya berbeda. Kalau kata Richard Feynman, “what I cannot build I do not understand”.
Tentu tujuan dari membuat vector search sendiri ini bukan untuk melepaskan diri sepenuhnya dari menggunakan layanan vector database yang sudah ada, terlebih karena mereka pasti dibangun oleh tim software engineer yang benar-benar ahli, bukan programmer pemula yang mengimplementasikan graph dengan data struktur hash map (dictionary pada python) karena tidak belajar DSA secara proper dan belum tahu cara menggunakan struktur data skip list. Tapi jelas, tidak ada salahnya belajar dan berbagi tidak harus menunggu sempurna.
Teaser
Jika diperhatikan, ada beberapa kekurangan dari metode HNSW yang sudah terimplementasi saat ini, sehingga performanya kurang optimal.
Pada episode selanjutnya saya akan membahas paramter-parameter yang bisa digunakan untuk meningkatkan performa dari vector search HNSW, dan bagaimana performa tersebut diukur.